Look both ways before crossing a one way street!
I had to develop a tool where I was supposed to extract specific data from a log file. The log file was really big. More than 2 million lines.
The log file was somewhat like this:
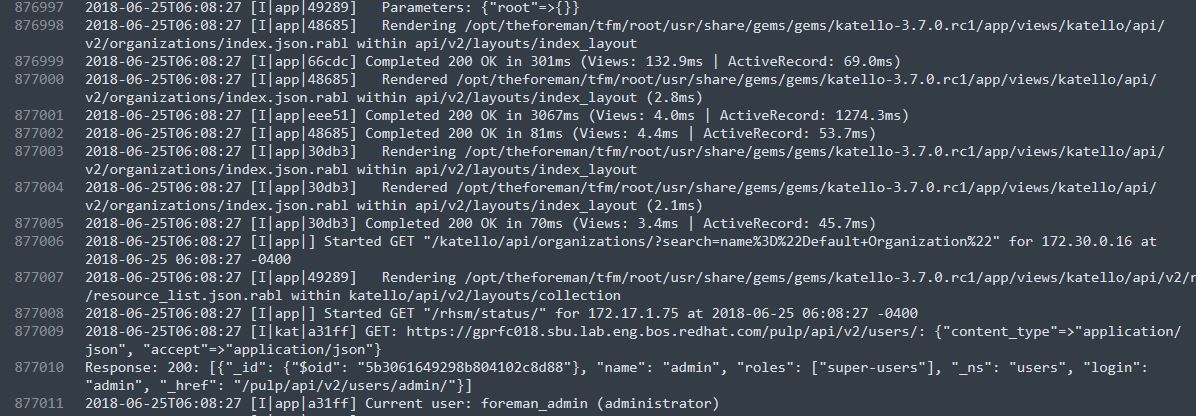
Log file consists of logs with some ID and timestamp. The Task was to extract terms like: "Time", "Totaltime", "Views" and "ActiveRecord" for each and every ID. For that, first I had to find Unique IDs in the log file, then find data corresponding to that particular ID and print accordingly. So, I followed this approach and wrote a Python script for this and it worked. The only problem was that it was taking a lot of time. Since, the file was really large so it was taking more than 3 hours to complete. It was not feasible as there were files with more than hundreds of millions of lines too.
This was the code that I first wrote:
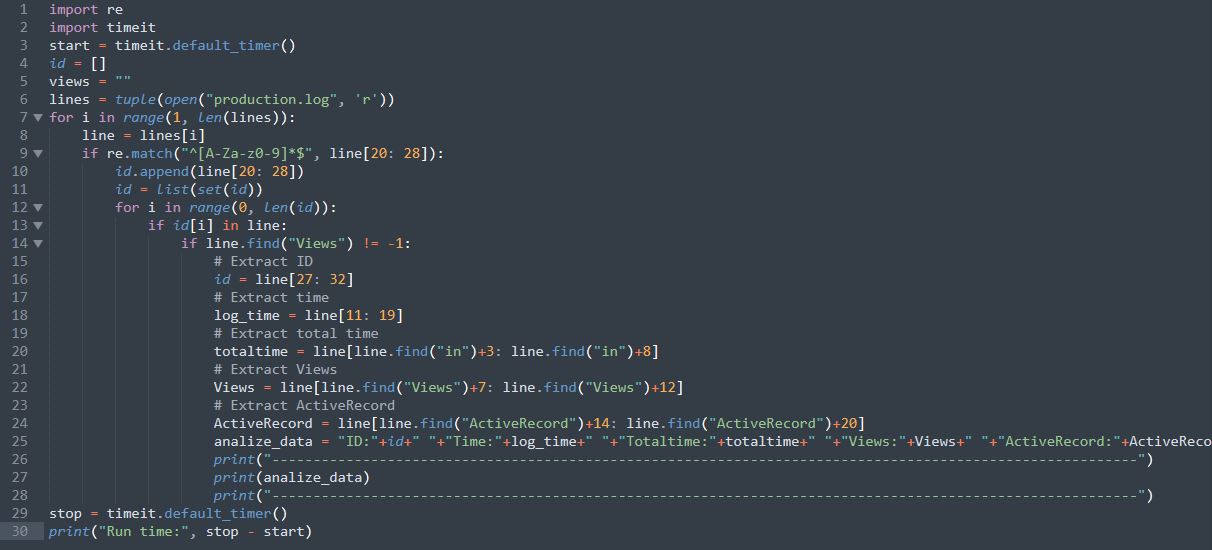
I tried to optimize this code as much as I could. I thought that it's complexity is O(n^2) so I tried to reduce that. Then I thought it is taking time to print data on terminal so I tried saving output to a file too. But the result was just the same. Then I thought of using Parallel processing too. Still, no good. I was using a system with 8 core i7 processor and 16 GB ram. I thought maybe the system is slow. So, I tried my code on one of my servers with 64 cores and 256 GB ram. But it was taking almost the same time. I got to know that the problem is with approach only. I wasn't able to do anything with my code with this approach. At last, I started debugging my code line by line to see which part is taking time, For once I also thought that Regex is consuming time, but it wasn't. Then after debugging line by line, I noticed that it was the data structures which were making my code slow. Both SET and LIST inside loops were the ones creating all the problem.
I had to rewrite the code with another approach as nothing worked. So, instead of finding unique IDs and extracting data according to each ID, I did just the opposite.
Code with new approach:
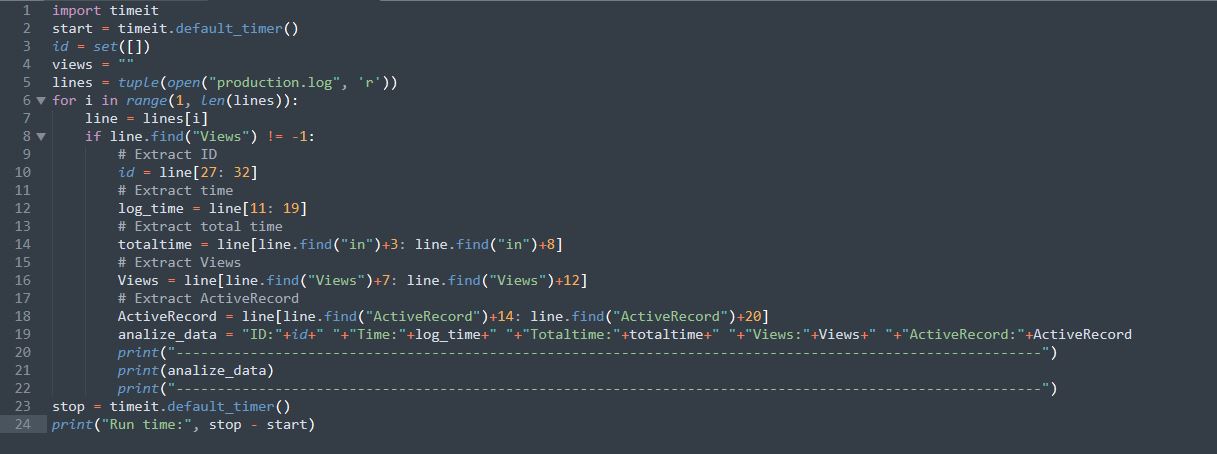
Here, it is looking for the data first and finding ID corresponding to that data which eventually finds all the unique IDs with data corresponding to them.
This was the output:
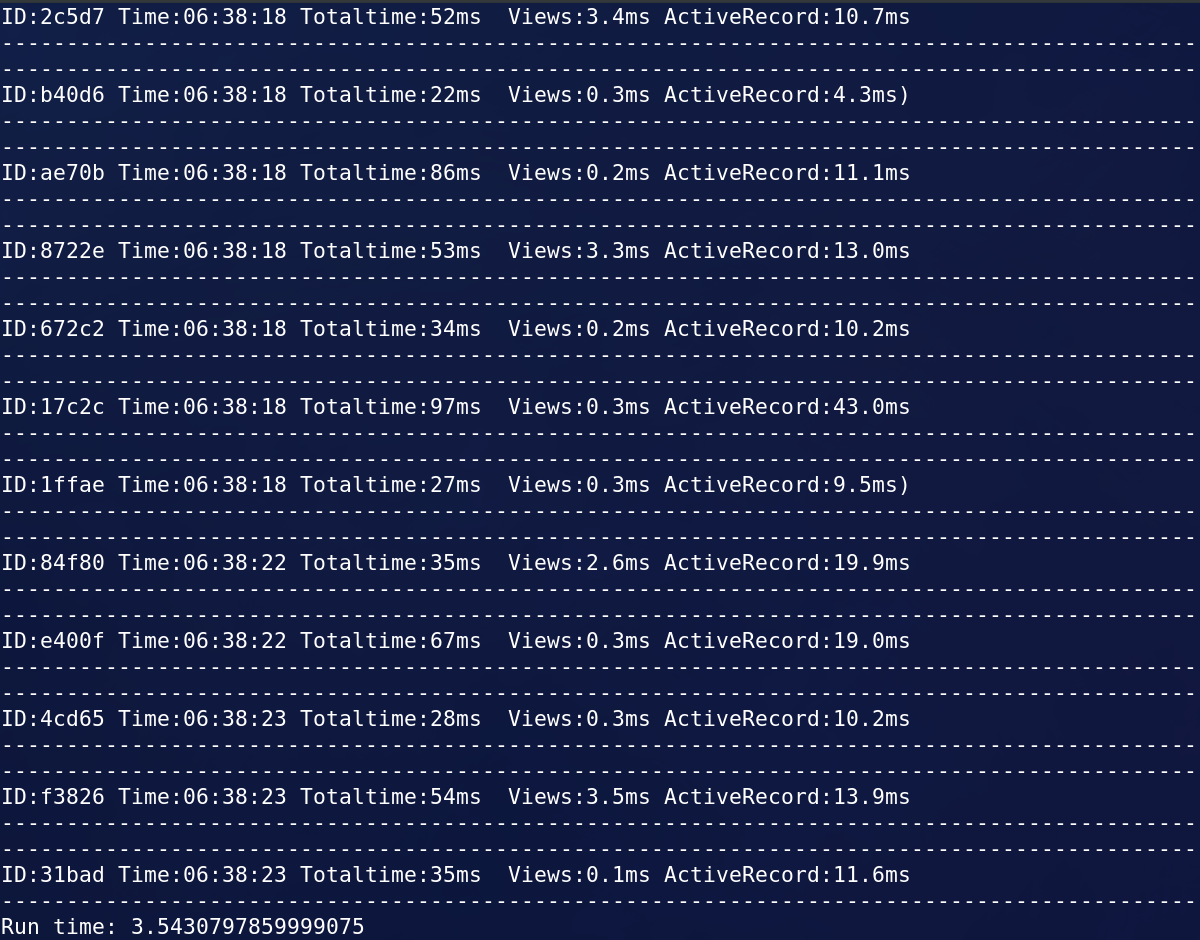
At first, it was taking more than 3 hours to complete. So, now the question is: How much time it took after all this struggle? Just 3.5 seconds!!.